
“请简述梯度下降算法以及如何优化梯度下降算法?”
梯度下降法
梯度下降是一个最优化算法,通俗的来讲也就是沿着梯度下降的方向来求出一个函数的极小值。
那么我们在高等数学中学过,对于一些我们了解的函数方程,我们可以对其求一阶导和二阶导,比如说二次函数。可是我们在处理问题的时候遇到的并不都是我们熟悉的函数,并且既然是机器学习就应该让机器自己去学习如何对其进行求解,显然我们需要换一个思路。因此我们采用梯度下降,不断迭代,沿着梯度下降的方向来移动,求出极小值。
批量梯度下降(Batch gradient descent)
现在我们就要求出J(θ)取到极小值时的θT向量。之前已经说过了,沿着函数梯度的方向下降就能最快的找到极小值。
$$\theta=\theta-\eta \nabla_\theta{J(\theta)}$$
计算
J(θ)关于θT的偏导数,也就得到了向量中每一个θ的梯度。沿着梯度的方向更新参数θ的值
迭代直到收敛。
批量梯度下降算法使用整个训练集计算目标函数的梯度并更新参数。代码如下:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
可以看到,批量梯度下降是用了训练集中的所有样本。因此在数据量很大的时候,每次迭代都要遍历训练集一遍,开销会很大,所以在数据量大的时候,可以采用随机梯度下降法。
随机梯度下降(Stochastic gradient descent)
和批量梯度有所不同的地方在于,每次迭代只选取一个样本的数据,一旦到达最大的迭代次数或是满足预期的精度,就停止。
可以得出随机梯度下降法的θ更新表达式。
$$\theta=\theta-\eta\nabla_\theta{J(\theta;x^{(i)},y^{(i)})}$$
因为每次只计算一个样本,所以SGD计算非常快并且适合线上更新模型。但是,频繁地更新参数也使得目标函数抖动非常厉害。
SGD频繁地参数更新可以使算法跳出局部最优点,更可能寻找到接近全局最优的解。SGD代码如下:
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
patams = params - learning_rate * params_grad
注意,上面的代码在每个epoch都对训练数据进行了打乱操作,这样可以保证不同epoch学习到的特征和训练样本的出现顺序没有关系。
使用情况
如果仅从测试误差出发,标准梯度下降的效果会比随机梯度下降要好。但是标准梯度下降的训练时间会比随机梯度下降要长。
像线性回归这种简单的模型,训练时间的优先级不高,所以用标准梯度下降会比随机梯度下降要好。像神经网络这种复杂的模型,训练时间的优先级比较高,所以用随机梯度下降比较好。
如果模型的损失函数是凸函数,那么使用标准梯度下降一定能达到全局最优。如果模型比较复杂,容易进入局部最优,那么使用随机梯度下降会发生震荡,容易从局部最优中跳出,进入全局最优。
另外,神经网络模型使用标准梯度下降最重要的原因是神经网络容易过拟合,而不是训练时间。
小批量梯度下降(mini-batch gradient descent)
小批量梯度下降结合了批量梯度下降和随机梯度下降的优点,它一次以小批量的训练数据计算目标函数的权重并更新参数。公式如下:
$$\theta=\theta-\eta\nabla_\theta{J(\theta;x^{(i:i+n)};y^{(i:i+n)})}$$
其中,n为每批训练集的数量,一般设为50到256。
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad
这个算法有下面几个方面的优点:
相比较SGD增加了一次更新使用的训练数据量,使得目标函数收敛得更加平稳;
可以使用矩阵操作对每批数据进行计算,大大提升了算法的效率。
梯度下降的优缺点
mini-batch gradient descent虽然相较于批量梯度下降和随机梯度下降方法效果有所改善但是任然存在许多挑战:
- 难以选择合适的学习速率:如果学习速率选择过小会造成网络收敛太慢,但是设得太大可能使得损失函数在最小点周围不断摇摆而永远达不到最小点;
- 可以在训练开始时设置一个较大地学习率然后每训练若干个周期后按比例降低学习率,虽然这个方法有一些作用,但是由于降低学习率的周期是人为事先设定的,所以它不能很好地适应数据内在的规律;
- 另一方面,我们对特征向量中的所有的特征都采用了相同的学习率,如果训练数据十分稀疏并且不同特征的变化频率差别很大,这时候对变化频率慢得特征采用大的学习率而对变化频率快的特征采用小的学习率是更好的选择。
- 这些梯度下降方法难以逃脱”鞍点”, 如下图所示,鞍点既不是最大点也不是最小点,在这个点附近,所有方向上的梯度都接近于0,这些梯度下降算法很难逃离它。

梯度下降算法的改进
冲量(Momentum)
实际中,我们遇到的目标函数往往在不同的维度上梯度相差很大,比如在下面的函数等高线图中可以看出函数在纵向上要比横向陡峭得多。
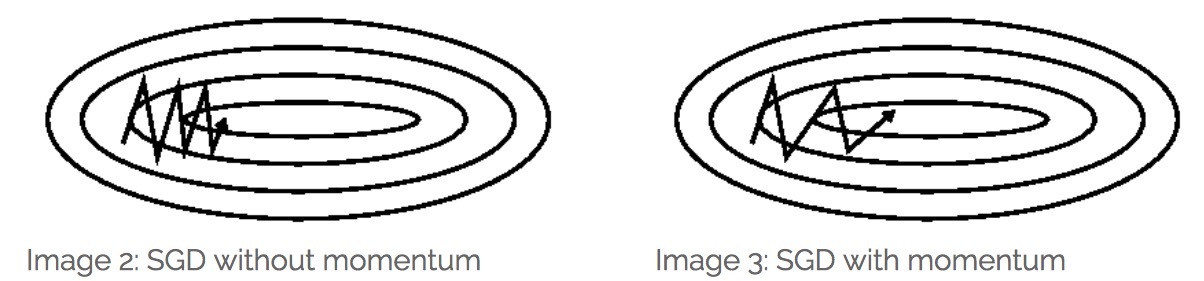
然而SGD等基本梯度下降算法并不知道这些,因为y方向梯度大x方向梯度小所以它们会在y方向上不断摇摆而沿x方向缓慢移动,但是我们知道在y方向的震荡是无用的只有x方向的才在不断接近最优点。
冲量方法在SGD的基础上,加上了上一步的梯度:

其中γ通常设为0.9。
由于目标函数在y方向上摇摆,所以前后两次计算的梯度在y方向上相反,所以相加后相互抵消,而x方向上梯度方向不变,所以x方向的梯度是累加的,其效果就是损失函数在y方向上的震荡减小了,而更加迅速地从x方向接近最优点。
也可以把这个过程和在斜坡放一个球让其滚下类比:当从斜坡顶端释放一个小球时,由于重力的作用小球滚下的速度会越来越快;与此类似,冲量的作用会使相同方向的梯度不断累加,不同方向的梯度相互抵消,其效果就是逼近最优点的速度不断加快。
Nesterov accelerated gradient
想象小球从山坡上滑落,它的速度沿着山坡不断加快,然而这并不是令我们满意的结果,当小球接近山谷(最优点)时,它已经有了很大的速度,很可能会再次冲向山谷的另一边,而错过了最优点。我们需要一颗更加“聪明”的小球,它能够感知坡度的变化,从而在它再次冲上山坡之前减速而避免错过山谷。
Nesterov accelerated gradient(NAG)就是一种让小球变“聪明”的方法。NAG不但增加了动量项,并且计算参数的梯度时,在损失函数中减去了梯度项将其作为下一次参数所在位置的预估:
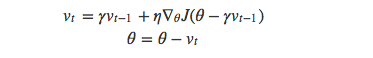
同样,上式中的γ 一般设为0.9。
如下图所示,蓝色的是动量方法的更新路径,首先计算一次梯度更新一小步,然后在下一次累加上一次计算的梯度从而更新一大步。而NAG算法每一步更新过程由两个步骤组成:第一步($\gamma v_{t−1}$, 图中棕色)使用之前计算的梯度移动一大步,第二步在移动后的位置计算的梯度方向移动一小步(图中红色线)进行修正,经过这样的两步合成了最终的绿线部分。
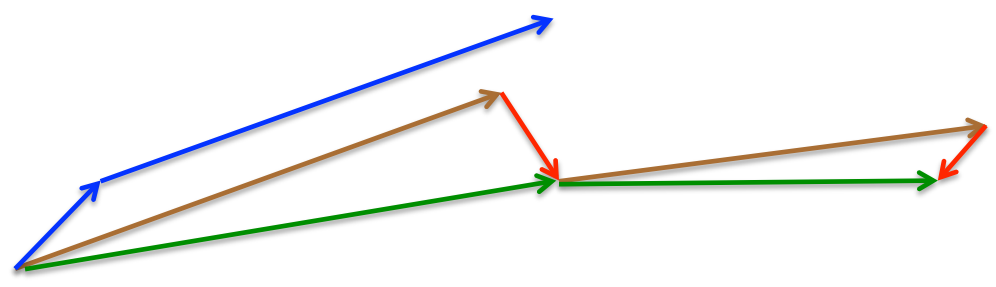
分析上面的原理可知,当“小球”将要冲上山坡的另一面时,红色线表示的预测梯度方向发生改变,从而将棕色向量往回拉达到了“减速”的效果。
通过NAG方法,我们使参数更新速率能够自适应“坡度”的变化,另一方面,我们希望每个单独的参数能够自适应各自的变化频率,比如,稀疏特征采用高的更新速率,其他特征采用相对较低的更新速率。下面介绍几种常用的方法。
详细介绍可以参见Ilya Sutskever的PhD论文Sutskever, I. (2013). Training Recurrent neural Networks. PhD Thesis.
Adagrad
Adadelta
RMSprop
Adam
Adam的全称是Adaptive Moment Estimation, 它也是一种自适应学习率方法,与Adadelta和RMSprop类似,它将每个参数的历史梯度平方均值存于$v_t$中,不同的是,Adam还使用了类似冲量的衰减项$m_t$:

效果
图a中,所有方法都从相同位置出发,经历不同的路径到达了最小点,其中Adagrad、Adadelta和RMSprop一开始就朝向正确的方向并且迅速收敛,而冲量、NAG则会冲向错误的方向,但是由于NAG会向前多“看”一步所以能很快找到正确的方向。

图b显示了这些方法逃离鞍点的能力,鞍点有部分方向有正梯度另一些方向有负梯度,SGD方法逃离能力最差,冲量和NAG方法也不尽如人意,而Adagrad、RMSprop、Adadelta很快就能从鞍点逃离出来。

参考资料
- http://www.cnblogs.com/Sinte-Beuve/p/6164689.html
- http://blog.csdn.net/ortyijing/article/details/54984058
- http://blog.csdn.net/bupt_wx/article/details/52761751
- http://blog.csdn.net/heyongluoyao8/article/details/52478715
- http://cs231n.github.io/neural-networks-3/
- http://www.360doc.com/content/16/1010/08/36492363_597225745.shtml
其中,第四个文章写得不错。

